Project Description
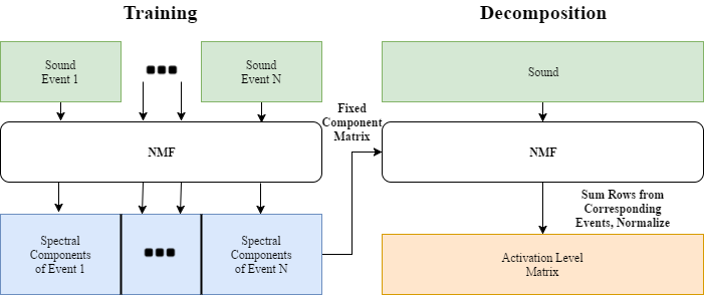
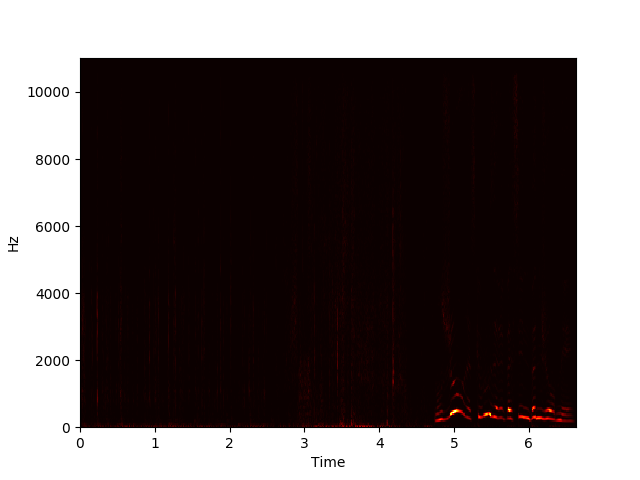
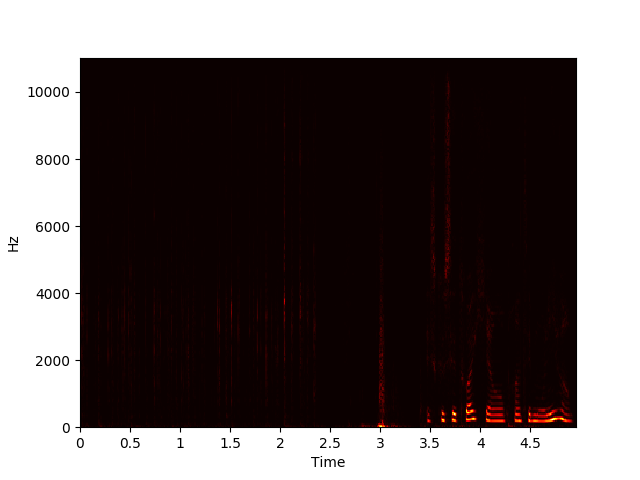
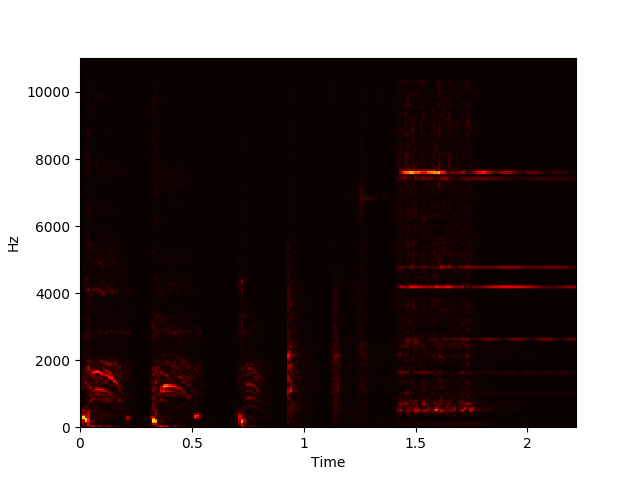
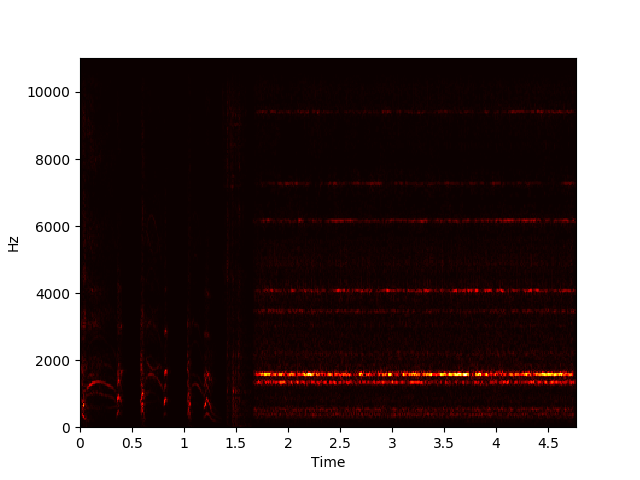
NMF aims to factorize a matrix X with dimensions m by n into a component matrix W with dimensions m by r and an activation matrix H with dimensions r by n, with r chosen beforehand, such that WH ≈ X. This can be done using gradient descent to minimize some cost function while updating the elements of W and H iteratively. Performing an NMF decomposition on a magnitude spectrogram should return unique repeating spectral components in W and a matrix of temporal activations of these components in H.
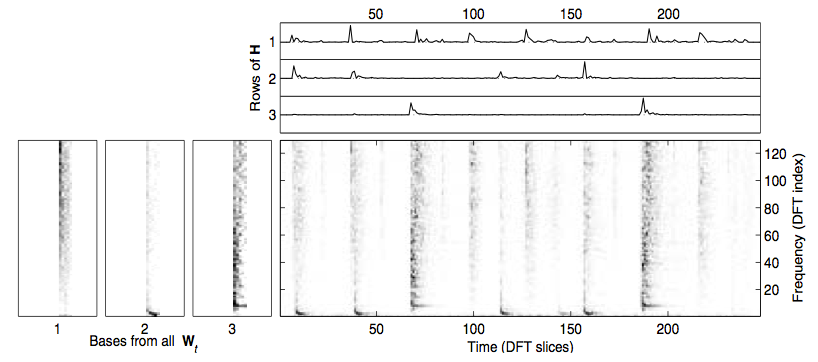
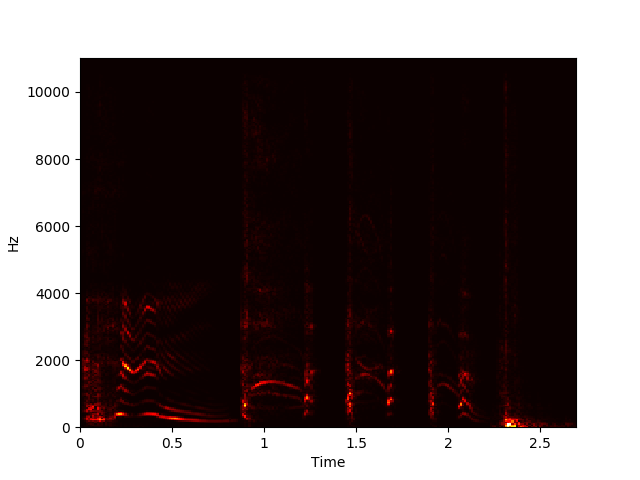
Example of NMF Decomposition on Spectrogram
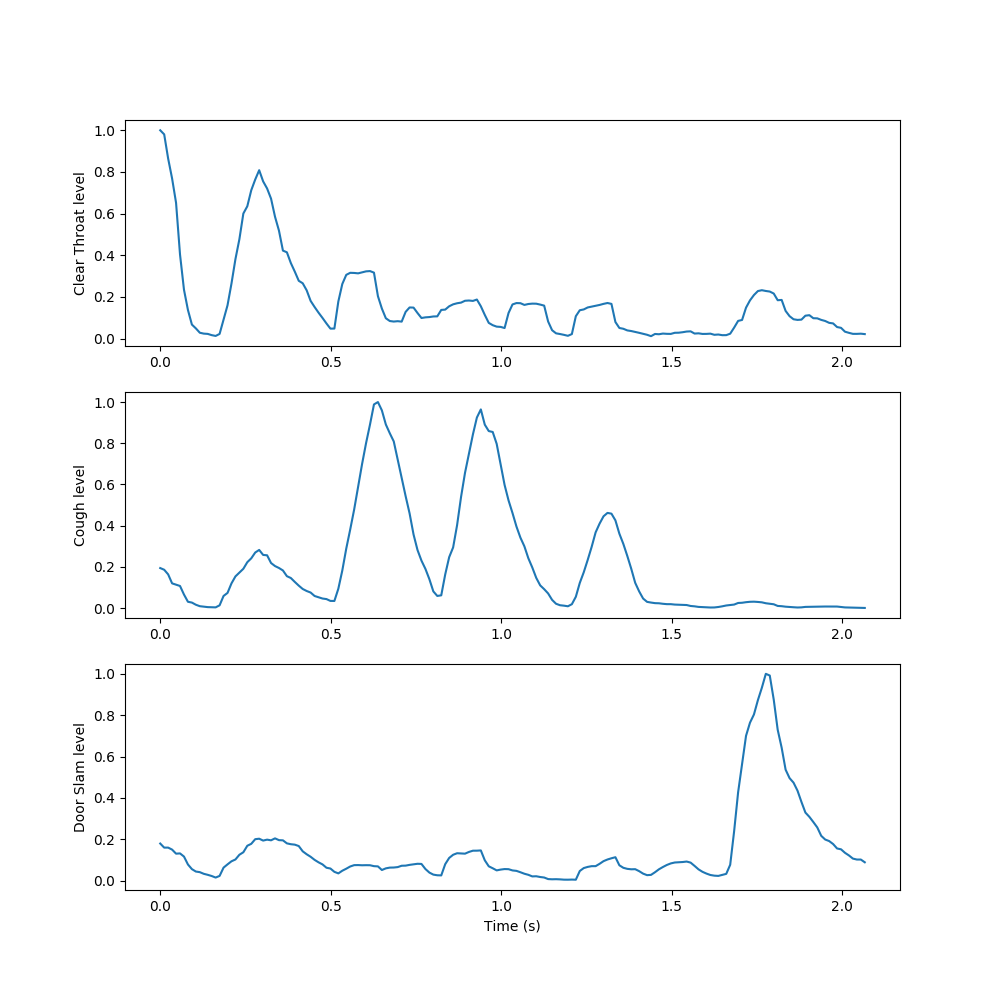
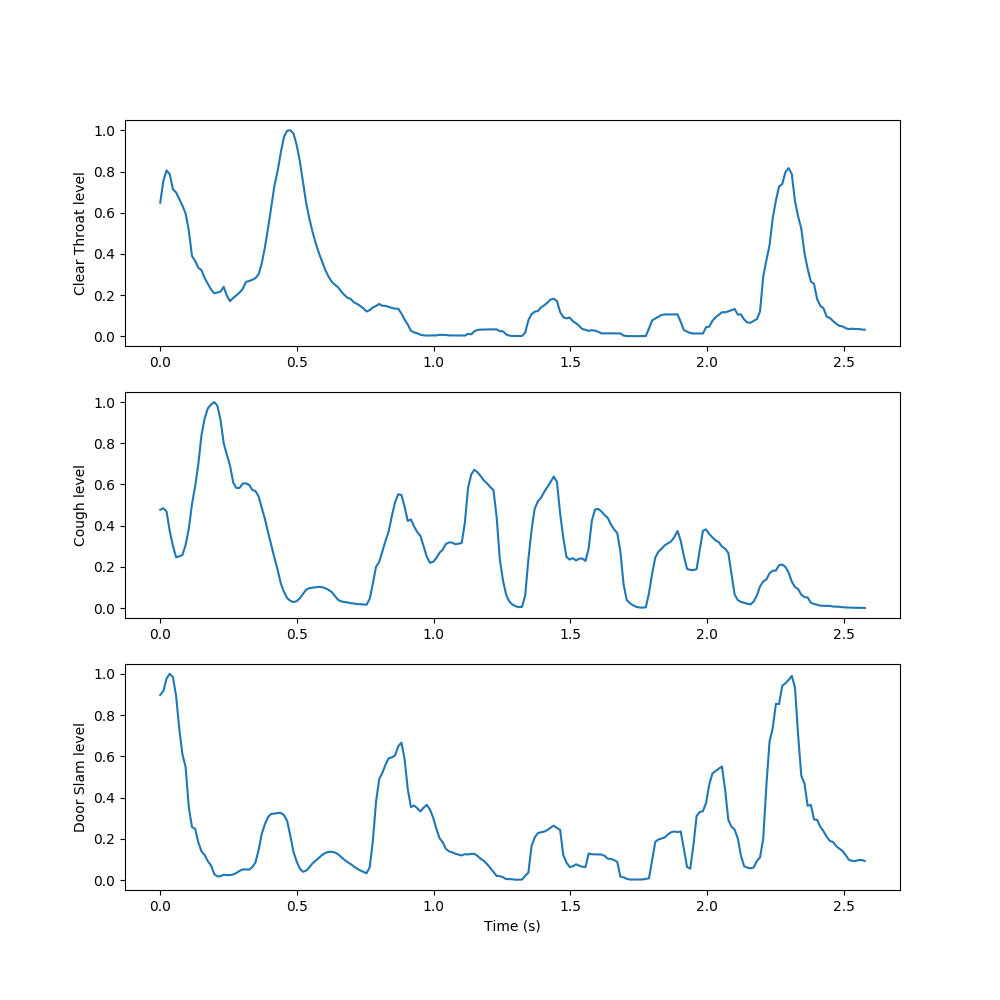
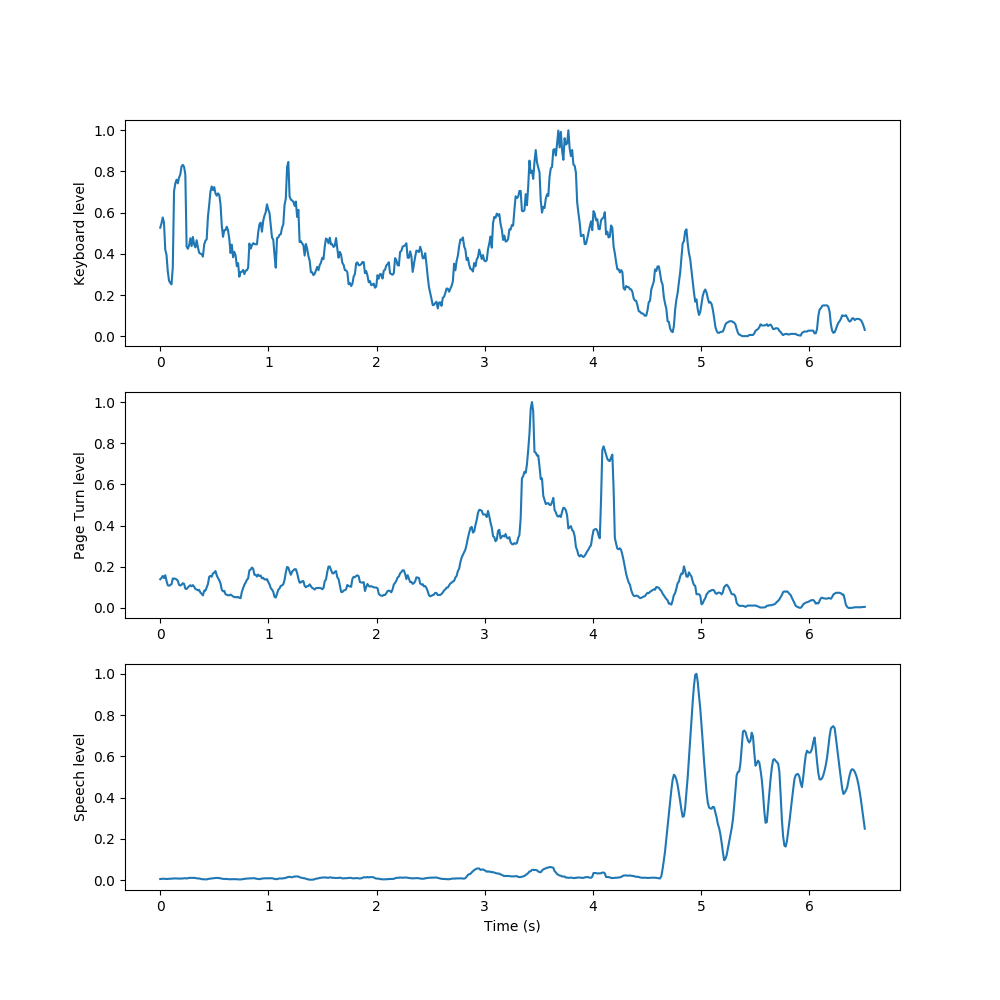
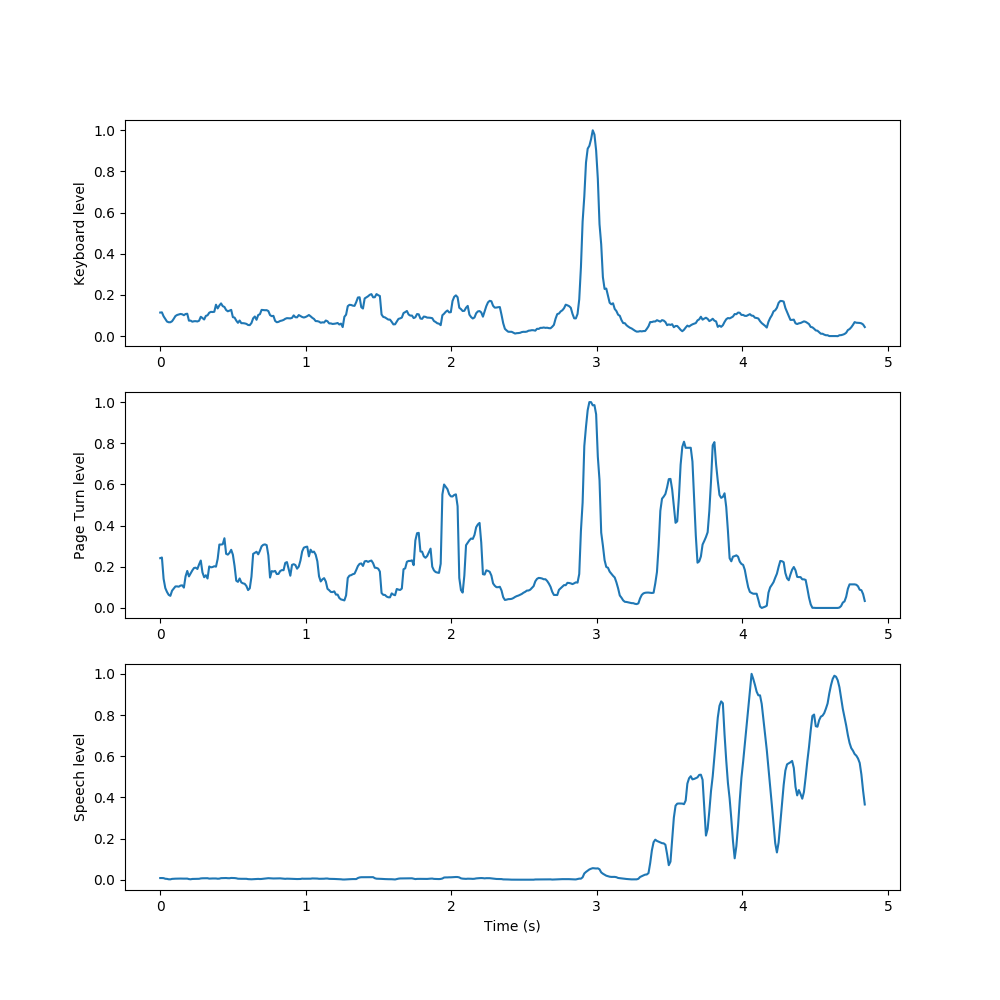
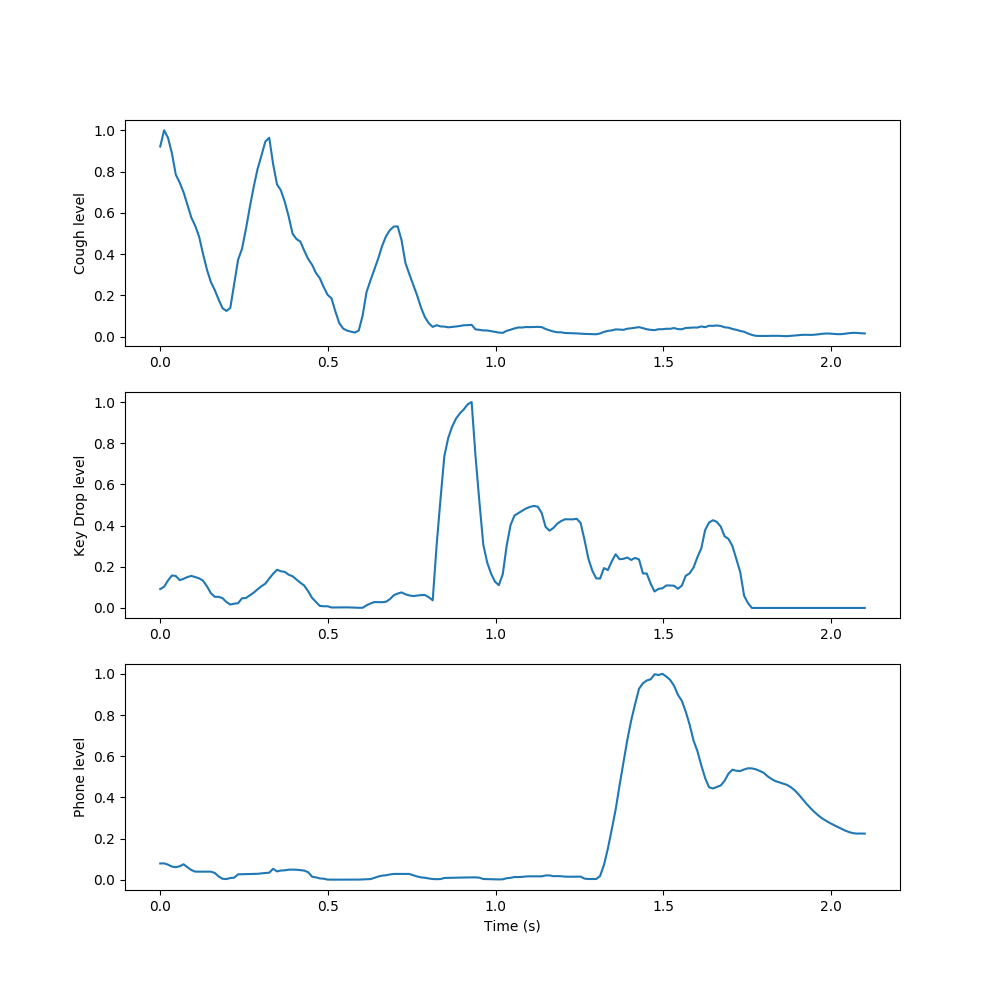
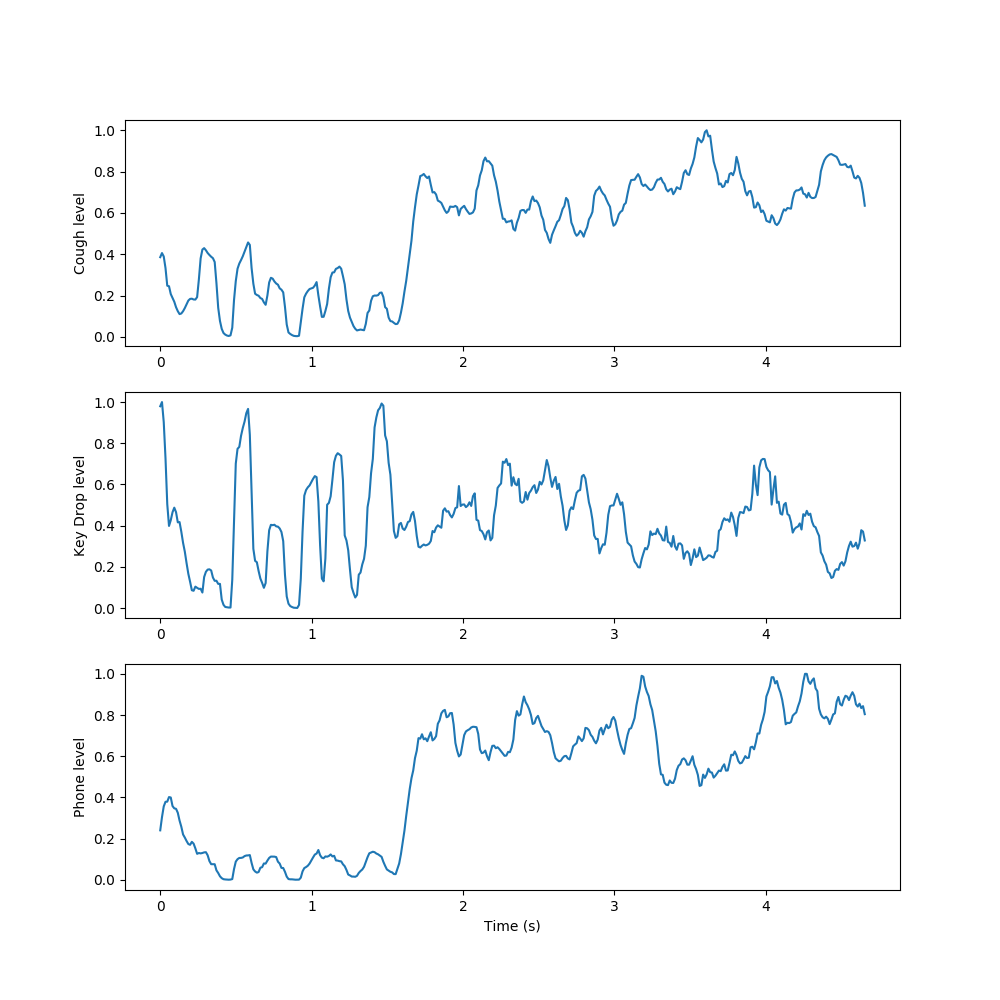
We used NMF to learn spectral components of examples of each sound class in the dataset, then appended these spectral components together to form an initial, fixed W to use in decomposing new sounds. We then condensed the resulting activations by summing the rows related to each learned event, taking a 10-frame moving average, and normalizing to yield a measure of each event’s activation level over time.